The configuration file can have one or more sample targets (or sample for short). A sample target aggregates information collected from one (or more) targets. The aggregated data is then sent off to one (or more) targets. The targets do this based on either the current time or when another target requests the data. Generally speaking, you want at least one sample target in MonAMI configuration files.
The read attribute describes from which monitoring targets a sample target should get its data. In its simplest form, this is a comma-separated list of monitoring targets. When fresh data is needed, the sample target will acquire data from all the named targets and aggregate the data. The following example takes data from a mysql and apache target.
[mysql] user = monami password = not-very-secret [apache] name = my-apache [sample] read = my-apache, mysql
Data is made available in a tree structure. sample
targets can select parts of the datatree rather than taking
all available data. Parts of a datatree are specified by
stating the path to the metric or branch of interest. A dot
(.) is used to separate branches within the
datatree. Also, parts of the tree can be excluded by
prefixing an entry with the exclamation mark
(!).
In the following example, the sample target takes the
threads data from the
my-apache target, but not the number of
threads in keep-alive state. The sample also aggregates data
from the mysql target's “uptime” value.
[mysql]
user = monami
password = not-very-secret
[apache]
name = my-apache
[sample]
read = my-apache.Threads, !my-apache.Threads.keep-alive, \
mysql.uptimeTimed samples are sample targets that have an interval attribute specified. Specifying an interval will result in MonAMI attempting to gather data periodically. This is useful for generating graphs or “push”ing data to reporting targets, such ganglia (see Section 3.5.3, “Ganglia”) or filelog (see Section 3.5.1, “filelog”).
The interval value specifies how long
the sample section should wait before requesting fresh data.
The time is given in seconds by default or as a set of
qualified numbers (an integer followed by a multiplier).
Following a number by s implies the number
is seconds, m implies minutes,
h implies hours, d
implies days and "w" implies weeks.
Here are some examples:
interval = 5every five seconds,
interval = 5severy five seconds,
interval = 2mevery two minutes,
interval = 3h 10severy three hours and 10 seconds.
When triggered by the timer, the sample target collects data and sends the aggregated data to one or more reporting targets. The write attribute is a comma-separated list of reporting targets to which data should be sent.
The following example records the number of threads in each state in a log file every 2 minutes.
[apache] [sample] interval = 2m read = apache.Threads write = filelog [filelog] file = /tmp/output
As with monitoring and reporting targets, a sample target can be assigned a name using the name attribute. These sample targets are named samples. If no name is specified then the sample is an anonymous sample. As with all other targets, named samples must have names that are unique and not used by any other target.
However, unlike named monitoring and reporting targets, it is OK to have multiple anonymous (unnamed) sample targets. Anonymous samples are given automatically generated unique names. Although it is possible to refer to an anonymous sample by its generated name, the form of these names or the order in which they are generated is not guaranteed. Using an anonymous sample's generated name is highly discouraged: don't do it!
Named samples can be used as if they were a monitoring target. When data is requested from a named sample, the sample requests data from its sources and returns the aggregated information. The following example illustrates this.
[mysql] user = monami password = something-secret [apache] [sample] name = core-services read = apache, mysql cache = 60s [sample] interval = 60s read = core-services write = filelog [filelog] file = /tmp/output
Adaptive monitoring is a form of internally-triggered monitoring that is not necessarily periodic. Under stable conditions, adaptive monitoring will be periodic; however, if the monitored system takes increasingly longer to reply (e.g., suffers increased load), adaptive monitoring will adjust by requesting data increasingly less often.
Overview
Fixed-period monitoring (e.g., monitoring once every minute) is commonly used to monitor services. This data can be plotted on a graph to show trends in activity, service provision, resource utilisation, etc. It can also be recorded for later analysis. It also allows status information (e.g., number of connected) to be converted into event-based information (e.g., too many connections detected) within a guaranteed maximum time.
When monitoring a service, the data-gathering delay (between the monitored system receiving a request for the current status and delivering the data) should be small compared to the time between successive requests. If you are asking a database for its current status once every minute, it should not take this database 50 seconds to reply! There are two reasons why this is important:
First, it is important that the monitored system is not overly affected by MonAMI. There may be no way of knowing whether an observed large data-gathering delay is due to MonAMI; but whatever the cause, it suggests that MonAMI should not be monitoring so frequently.
Second, MonAMI has no idea whether the data-gathering delay occurred before the service recorded its current state or after. If the size of this uncertainty is about the same size as the sample's interval, then there's little point sampling this often.
Rather than maintaining a constant sampling period (e.g., once every minute), adaptive monitoring works by maintaining a constant duty-cycle. The duty-cycle is the percentage of the period spend “working”. If an activity is repeated every 40 seconds with the system active for the first 10 seconds the duty cycle is 25%; if the situation changes so it's now active for 30s every 40s then the duty cycle will have increase to 75%.
Whenever MonAMI acquires data from a monitored service, it keeps a record of how long it took to get the monitoring data. It uses that information to adjust an estimate of how long the next data acquisition will take. The process is described in Section 3.3.4, “Estimating future data-gathering delays”. This estimate, along with the desired sampling period allows MonAMI to estimate the duty-cycle of the next sample. MonAMI can then adjust the sampling period to try to keep this close to the desired duty-cycle.
In addition to the desired duty-cycle, there are two other parameters that affect adaptive monitoring: a lower- and upper- bound on the delay.
The lower-bound on the delay is the smallest delay between successive requests MonAMI will allow. If a service is so lightly loaded that it is responding almost instantaneously then the lower-bound limit will prevent MonAMI from sampling too fast. The interval attribute gives the lower-bound when MonAMI is adaptively sampling.
The upper-limit is the largest delay between successive requests: the adaptive monitoring will not sample less frequently that this limit. This is useful should, for whatever reason, a service takes an anomalously long time to reply. Without an upper-limit, MonAMI would adjust the sampling interval to compensate for this anomalous delay and might take an arbitrarily long time to return to a more normal sampling period. The sample's limit attribute provides this upper-limit to adaptive monitoring.
Adaptive monitoring as a safety feature
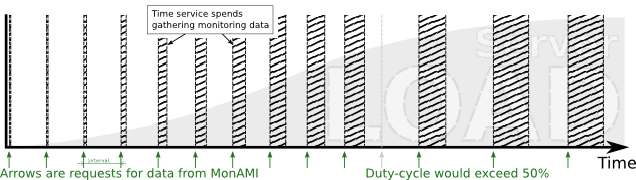
Adaptive mode is enabled by default with a target duty-cycle of 50%. This is meant as a safety feature and anticipates that the observed duty-cycle, under normal conditions, will be less than 50%: if sampling once every minute, we expect gathering of data to take less than 30 seconds.
Whilst the duty-cycle is low, MonAMI will conduct periodic sampling; however, should the measured duty-cycle exceed the 50% limit, the monitoring will switch into an adaptive mode and MonAMI will sample less often. This could be due to any number of reasons; but, once the system has recovered and the duty-cycle has dropped to below the 50% limit, MonAMI will switch off the adaptive timing and resume periodic monitoring.
If MonAMI switches to adaptive monitoring too often then the 50% target may be too low or the sample interval is set too small. Either sample less often (increase the interval attribute) or set an explicit dutycycle attribute value greater than 50%. Specifying a dutycycle value of zero will disable adaptive mode, and so enforce periodic monitoring.
There is currently no support within MonAMI for extending the adaptive monitoring support to include on-demand monitoring flows. This is because none of the currently available on-demand reporting systems provide the facility to indicate that they should sample less frequently.
Adaptive monitoring by default
If a sample target's dutycycle attribute is set to a desired duty-cycle and the interval attribute value is set sufficiently small then the sample will operate in adaptive mode by default. Adaptive monitoring is then elevated from a safety feature to being the normal mode of operation for this sample target.
If no interval is set, a default interval value of one second is used. This places a lower-bound on the sampling frequency: MonAMI will not attempt to monitor more frequently than once per second.
Adaptive monitoring has strengths and weaknesses compared to periodic monitoring. There is greater certainty that the monitoring is not overly affecting your monitored systems. However, adaptive monitoring is a new feature. Support within the various reporting systems for this mode of operating will vary, and analysing the resulting data is more complex.
In summary, each sample section accepts the following options:
- interval period, optional
specifies how often data should be collected. The format is a series of numbers, optionally qualified, separated by white space, for example
1h 2m 30swould repeat every 1 hour, 2 minutes and 30 seconds. Seconds is assumed if no qualifier is specified. The total interval is the sum of all numbers present.If no interval and no duty-cycle is specified, the sample will never trigger data acquisition. Instead it will act as an aggregator of data, requesting data only on-demand.
If a dutycycle attribute is specified, the interval attribute specifies a lower-bound on the sampling period during adaptive mode monitoring. If no interval is specified, a default lower-bound of one second is used. Setting an interval of zero permits arbitrarily short sample periods (not recommended).
- read string, required
a read string specifies which sources to query and which information to report back. The format is a comma-separated list of definitions. Each definition is either a target name or a target name, followed by a period (
.), followed by the name of some part of that target's datatree. If only the target is specified, the whole datatree is referred to; if the part of the datatree referred to is a branch-node, then any data below that branch is referred to. Any definition can be negated by starting with an exclamation mark (!), which makes sure that element is not included in the report. For example:foo, bar, !bar.unimportant, baz.important
would include all data from
foo, all frombarexcept that within thebar.unimportantbranch, and data frombazcontained within theimportantbranch. The namesfoo,barandbazare either defined by some target's name attribute, or the default name taken from the target's plugin name.- write string, optional
a comma-separated list of targets to whom the collected information will be sent. This attribute must be specified if the sample is internally triggered (either interval or dutycycle attributes are set).
- dutycycle percent, optional
the desired or threshold duty-cycle value for monitoring using adaptive mode. MonAMI will measure and adjust the sampling period to keep the measured duty-cycle less than or equal to this value. Upper- and lower-bounds will prevent sampling too infrequently or too often. If the interval attribute is specified but dutycycle is not, a default value of 50% is used.
- limit period, optional
The upper limit to the sampling period for adaptive monitoring. MonAMI will never sample less frequently that this. If not specified, a default value is used. The default value is twenty times the interval attribute, if specified, or twenty minutes if not.