In this section we will tell MonAMI to record everything it knows about something periodically. This will introduce periodic monitoring, which is perhaps the most common monitoring activity.
Plugins and Targets
Before looking at the configuration, it would help to understand two concepts within MonAMI: plugins and targets.
Plugins are fundamental to MonAMI. They allow information to be gathered, stored, or otherwise processed. Most plugins come in one of two types: either monitoring or reporting.
Monitoring plugins are those that provide information. A monitoring plugin understands how to obtain information from a specific service, program or other source of information. All the peculiarities with obtaining that information are concealed within the plugin, so they provide a uniform method of obtaining information. The filesystem and apache plugins are examples of monitoring plugins. Both are available within the default package.
Reporting plugins will accept monitoring information. They will either store this information or send it to some monitoring system. The snapshot plugin is an example of a reporting plugin. It will store all information it is given as a file, overwriting any existing content.
There are yet other plugins that lead a more complex life, such as the sample and dispatch plugins. Don't worry about these just yet: they'll become clear further along. Some of the aspects of the sample plugin are mentioned here, but both plugins will be explored more in later sections.
In all, MonAMI comes with many useful plugins and the number grows
with each release. They are all described within the MonAMI User
Guide and brief synopses are included within the system manual
(man page) entry on the
configuration file format.
Targets are configured instances of a plugin. They exist only when MonAMI is run and are described by the MonAMI configuration files; for example, whilst the mysql plugin knows (in principle) how to monitor a MySQL server, it is a target (that uses the mysql plugin) that knows how to monitor a specific MySQL server instance running on a particular machine, using a particular username and password.
As with plugins, a monitoring target is a target that provides MonAMI with information. It is a configured monitoring plugin. Likewise, a reporting target is a target that accepted information and is based on a reporting plugin.
An easy way to illustrate the difference between plugins and targets is to consider monitoring several partitions. The filesystem plugin will monitor a partition. To monitor multiple partitions, one would configure multiple filesystem targets. Each of these targets will use the filesystem plugin. Although there may be several filesystem targets, there is only one filesystem plugin.
Configuration file
The example configuration file used in this section will tell
MonAMI to measure the current status of the root filesystem every
two seconds and store all the data in the file
/tmp/monami-filesystem. Copy the text below
and store it as the
/etc/monami.d/example.conf file.
## ## MonAMI by Example, Section 2 ## # Monitor our root filesystem [filesystem] ❶ location = / ❷ name = root-fs ❸ # Record latest f/s stats every two second [sample] ❹ read = root-fs write❺ = snapshot interval❻ = 2 # The current filesystem statistics [snapshot] ❼ ❽ filename = /tmp/monami-filesystem
The following points are worth noting:
The configuration file is split into stanzas, each of which starts with a line containing the name of a plugin in square brackets. In this case, the filesystem plugin is mentioned. Each stanza creates a new target that uses the specified plugin. | |
Stanzas can have multiple attribute lines describing how the target should behave. Each attribute line has a keyword, followed by an equals sign, followed by the value (white space is also allowed). Some plugins require certain attributes to be specified; other attributes are optional. | |
Each target has a name, which must be unique. The name attribute allows you to configure what a target's name should be. | |
Sample targets collect together data and send it somewhere. They are also somewhat special: you can specify any number without explicitly giving them unique names. | |
On receiving fresh data, the sample target will deliver it to the targets named in the write attribute. | |
If a interval attribute is configured, this will be triggered periodically. It states how often the sample target will request fresh data. | |
The snapshot plugin accepts data and writes it to disk. The sample sends data to the snapshot target, which then writes this data to the disk. | |
If there is no name attribute, the target will take its name from the plugin. Naturally, this only works if a single target (at most) is created for each plugin. |
The sample's interval attribute states how
often the sample section will request fresh data. This happens
every two seconds in this example (written as
2s or just 2). The
interval can also be specified in minutes
(e.g., every five minutes is 5m), in hours
(e.g., every six hours 6h), or in combinations
of these (e.g., 1h 30m).
Fast enough?
MonAMI's internal time-keeper works with a time granularity of one second: once-per-second is the maximum rate that MonAMI can gather data. In fact, there is no particular technical reason that for forcing this maximum rate, but there is also no compelling reason to increase the maximum sampling rate.
At its heart, MonAMI is asynchronous. It can also gather and store data very quickly. When MonAMI is configured for event-based monitoring, it can store data with low latency: far faster than once per second. If you think that once-per-second is too slow, perhaps you can recast your monitoring requirement as one based on event-based monitoring.
Running the example
Make sure you run MonAMI for at least two seconds. When starting up, MonAMI attempts to spread its work evenly to reduce the impact of monitoring. It does this by starting the timed monitoring with a random fraction of the interval time. It can take up to two seconds before MonAMI will monitor the root filesystem in the example above.
Once data is collected, you should see the file
/tmp/monami-filesystem. Depending on your
local filesystem (and which version of MonAMI you are using) you
should see output similar to the following:
"root-fs.fragment size" "1024" (B) [every 2s] "root-fs.blocks.size" "1024" (B) [every 2s] "root-fs.blocks.total" "264445" (blocks) [every 2s] "root-fs.blocks.free" "142771" (blocks) [every 2s] "root-fs.blocks.available" "129118" (blocks) [every 2s] "root-fs.capacity.total" "258.24707" (MiB) [every 2s] "root-fs.capacity.free" "139.424805" (MiB) [every 2s] "root-fs.capacity.available" "126.091797" (MiB) [every 2s] "root-fs.capacity.used" "118.822266" (MiB) [every 2s] "root-fs.files.used" "68272" (files) [every 2s] "root-fs.files.free" "56294" (files) [every 2s] "root-fs.files.available" "56294" (files) [every 2s] "root-fs.flag" "0" () [every 2s] "root-fs.namemax" "255" () [every 2s]
Data and datatrees
Monitoring targets will often provide lots of information, often more than you actually want. To keep this information manageable, it is held in a tree structure, just like a filesystem: files correspond to a specific metric and directories (or folders) containing other directories and metrics.
The datatrees can be drawn as graphs. The example datatree, shown in the above snapshot output, is shown in Figure 1. The ellipses represent branches and the rectangle represents metrics.
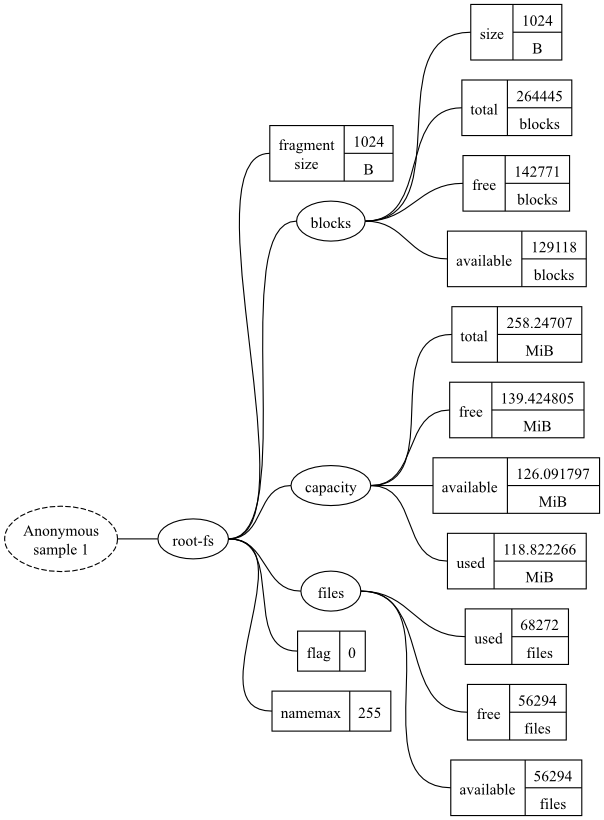
To refer to a specific metric, you specify a path within the
datatree, ignoring the very first element (shown as a dashed
ellipse) as it is redundant. This is similar to how a file has an
absolute path within a filesystem. Instead of using a slash
(/ or \) to separate
elements of a metric's path, a dot is used. So the metric in the
lower right corner of the diagram is
root-fs.files.available.