Information needs to go somewhere for it to be useful. MonAMI's job is to take data from one or more monitoring targets and send it somewhere or (more often) to multiple destinations. Reporting plugins deal with “sending data somewhere” and the reporting targets are configured reporting plugins to which data can be sent.
As with monitoring targets, all reporting targets need a unique name. By default a reporting target will adopt the plugin's name. As with monitoring targets, it is recommended to set a unique, meaningful name for each reporting target in complex configurations.
The filelog plugin stores information within a file. The
file format is deliberately similar to standard log files, as
found in the /var/log filesystem hierarchy.
New data is appended to the end of the file. Fields are separated
by tab characters and each line is prefixed by the date and time
when the data was taken.
If the file does not exist, it is created. When the file is
created, a header line is added before any data. This line starts
with the hash (#) symbol, indicating that the line
does not contain data. The header consists of a tab-separated
list of headings for the data. This list is correct for the first
row of data. If the data is aggregated from multiple monitoring
targets, then the order of those targets is not guaranteed.
Attributes
- filename string, required
the full path of the file into which data will be stored.
The FluidSynth project provides code (a library and a program) that accepts MIDI (a standard music interface) information and provides a MIDI-like API, providing high-quality audio output. The fluidsynth software is based on the SoundFont file format. Each SoundFont file contains sufficient information to reproduce the sound from one or more musical instruments. These SoundFont files might include instruments of an orchestra, special effects (e.g., explosions) or sounds taken from nature (e.g., thunder or a dog barking). More information about fluidsynth can be found on the fluidsynth home page.
The fluidsynth plugin renders information as sound. The presence of sound might indicate a problem, or the pitch of the note might indicate how hard some application is working.
To achieve sound, the plugin either connects to some fluidsynth program or uses the fluidsynth library API, depending on how it is configured. If the configuration specifies a host attribute, then the plugin will attempt to connect to the fluidsynth program running on that host. If no host attribute is specified, then the fluidsynth plugin will use the fluidsynth library to configure and start a new fluidsynth instance.
When running the embedded fluidsyth code, the plugin requires at
least one soundfont attribute. These attributes
describe where the SoundFont files are located. Each
soundfont attribute is a comma-separated list,
specifying the short name for that file (used for the
note attributes) and the location of the SoundFont
file: short name ,
path to SoundFont file
An example soundfont attribute is:
soundfont = hi, /usr/share/SoundFonts/Hammered_Instruments.sf2
Using remote fluidsynth
When the plugin is connecting to a SoundFont program running independent of MonAMI, all soundfont attributes are ignored. Instead, all SoundFonts must be loaded independently of MonAMI. The easiest way of achieving this it to specify the SoundFont files as command-line options. For example:
fluidsynth -nis /usr/share/SoundFonts/Hammered_Instruments.sf2
Making sounds
The note attributes describe how sound is generated. The attribute has seven comma-separated values, like this:
note =sf,bank,pgm,note-range,duration,source,data-range
These attributes have the following meanings.
-
sf When no host attribute has been specified (i.e. using the fluidsynth library API), this is the short name for the SoundFont to use as described in soundfont attributes.
When connecting to a fluidsynth program, this is the (integer) number of the SoundFont to use. The first loaded SoundFont file is numbered 1.
-
bank This is the MIDI bank within the SoundFont to use. A MIDI bank is often a family of similar instruments. The available options will depend the loaded SoundFont files, but most SoundFonts will define instruments in bank 0.
-
pgm This is the MIDI program to use for this note. A program is a unique number for an instrument within a specified MIDI bank. General-MIDI defines certain programs to be named instruments, some SoundFonts follow General-MIDI for bank 0.
-
note-range This details which notes (pitches) might be played. For example,
note-range53if only a single note pitch is needed, or20-59to specify a range of notes. The range of notes must specify the lower note first.-
duration This is the duration of the note, in tenths of a second (or deciseconds). A
duration20results in a two-second note and5results in notes that last for half a second (500 ms).-
source This is the path in a datatree for the information. The metric can be an integer number, a floating-point number or a string.
If the metric is an integer or floating-point number then the metric value is used to decide whether the note should be played and if so, at which pitch.
If the metric has type string, then the metric's value is checked to see if a note should be played. For string metrics, the
note-range-
data-range This is the valid range of data that will produce a note.
If the metric has a string value, then the
data-rangeIf the metric has a numerical result, the
data-range0-10or10-0).Metric values in that range will cause a note to be played. The pitch of the note increases as the metric value tends towards the second number. With the
data-range0-10a metric value of 10 produces the highest pitch note; with thedata-range10-0a metric value of 0 produces the highest pitch note.Either number (or both) can be sufficed by a caret symbol (
^) indicating that numbers outside the range should be truncated to this value. Adata-range0-10^indicates that metric values greater than 10 should produce notes as if 10 was observed, but that any measurements less than 0 should be ignored, and so not played.
Here are some example note attributes with brief explanations.
note = hi, 0, 35, 60, 10, apache.severity, error
Play note 60 of program (instrument) 35, bank 0 of the
hi SoundFont file for a duration of 10 deciseconds
(or 1 s) if the apache.severity metric has a
value of error. If the datatree provided contains no
apache.severity then no note is sounded.
note = 1, 0, 3, 38-80, 2, apache.transferred, 0 - 4096^
Play program (instrument) 3, bank 0 of the first loaded SoundFont for 2 decisecond (0.2 s) with the pitch dependant on the size transferred. The note range is 38 to 80, with corresponding values of 0 kB to 4 kB: higher metric values result in higher pitch notes. Values of transfer size greater than 4 kB are played, but truncated, resulting in a note at pitch 80 being played.
note = hi, 0, 75, 60-80, 4, apache.Threads.waiting, 10^ - 0
Play program 75, bank 0 of the hi SoundFont for 4
deciseconds (0.4 s) based on the number of threads in
waiting state. Note 80 is played when 10 (or more)
threads are in waiting state; note 60 if there is no thread in
this state; if there are 1 to 9 threads, the results are somewhere
in between.
There are a number of other options that may improve the performance of the embedded fluidsynth engine. They are described briefly in the summary of this plugin's options below,
Attributes
- soundfont string, ignored/required
a comma-separated list of a nickname and an absolute path to the SoundFont file. The attribute may be repeated to load multiple SoundFont files. When using the fluidsynth library, the soundfont attributes are required; when connecting to a external fluidsynth program these attributes are ignored.
- note string, required
Each note attribute indicates sensitivity to some metric's value. Multiple note attributes may be specified, one for each metric.
The note attribute values are a comma-separated list. The seven items are: the SoundFont short-name or instance count, bank (integer), program (integer), note-range, duration (integer), source (datatree path), data-range. The SoundFont short-name is defined by the soundfont attribute.
- bufsize integer, optional
the desired size for the audio buffers, in Bytes. This is ignored when connecting to an external fluidsynth program.
- bufcount integer, optional
how many audio buffers there should be. Each buffer has size given by the bufsize attribute. This attribute is ignored when connecting to an external fluidsynth program.
- driver string, optional
the output driver. The default is “ALSA”. Other common possibilities are “OSS” and “JACK”. This attribute is ignored when connecting to an external fluidsynth program.
- alsadevice string, optional
the output ALSA device. Within MonAMI, the default is “
hw:0” due to performance issues with the ALSA default device “default”. This attribute is ignored when connecting to an external fluidsynth program.- samplerate integer, optional
the sample rate to use (in Hz). The default will be something appropriate for the sound hardware. This attribute is ignored when connecting to an external fluidsynth program.
- reverb integer, optional
whether the reverb effect should be enabled. “0” indicates disabled, “1” enabled. Default is enabled. Disabling reverb may reduce CPU impact of running fluidsynth. This attribute is ignored when connecting to an external fluidsynth program.
- chorus integer, optional
whether the chorus effect should be enabled. “0” indicates disabled, “1” enabled. Default is enabled. Disabling chorus may reduce CPU impact of running fluidsynth. This attribute is ignored when connecting to an external fluidsynth program.
- maxnotes integer, optional
the maximum number of concurrent notes. If more than this is attempted, some notes may be silenced prematurely. This attribute is ignored when connecting to an external fluidsynth program.
Ganglia is a monitoring system that allows multiple statistics to be gathered from many machines and those statistics plotted over different time-periods. By default, it uses multicast to communicate within a cluster, and allows results from multiple clusters to collated as a single “grid”. More information about Ganglia can be found within the Ganglia project site and a review of the Ganglia architecture is presented in the paper the ganglia distributed monitoring system: design, implementation, and experience..
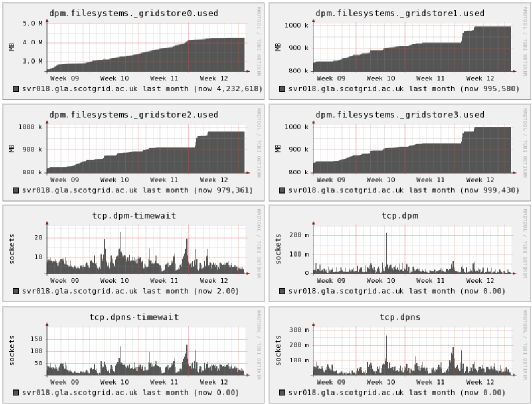
Ganglia comes with a standard monitoring daemon (gmond) that monitors a standard set of statistics about a particular machine. It also includes a command-line utility (gmetric) that allows for the recording of additional metrics.
The MonAMI ganglia plugin emulates the gmetric program and can send additional metrics within a Ganglia-monitoring cluster. These appear automatically on the ganglia web-pages, either graphically (for graphable metrics) or as measured values.
Note
Please note that there is a bug in Ganglia prior to v3.0.0 that can result in data corruption when adding custom data. MonAMI will trigger this bug, so it is strongly recommended to upgrade Ganglia to the latest version.
Network configuration
The Ganglia gmond daemon loads its configuration from a file
gmond.conf. For some distributions, this
file is located at /etc/gmond.conf, for other
it is found at /etc/ganglia/gmond.conf. The
ganglia plugin can parse the
gmond.conf file to discover how it should
deliver packets. It searches both standard locations for a
suitable file. If found, it will use the setting contained within
the file, so no further configuration is necessary. If a suitable
gmond configuration file exists at some other location, the
plugin can still use it. The config
attribute can be set to the config file's location.
Although it is recommended to run MonAMI in conjunction with gmond, this is not a requirement. In the absence of a suitable gmond configuration file, the multicast channel and port to which metric updates should be sent can be set with the multicast_ip_address and multicast_port attributes respectively. By default, the kernel will choose to which network interface the multicast traffic is sent. If this decision is wrong, the interface can be specified explicitly using the the multicast_if attribute.
Serialisation
MonAMI uses a tree-structure for storing metrics internally. In contrast, Ganglia uses a flat name-space for its metrics. To send data to Ganglia, the metric names must be “flattened” to a simple name.
To obtain the Ganglia metric name, the elements of the metric's
path are concatenated, separated by a period (.)
character. For example, the metric
torque.Scheduler.period is the period, in seconds,
between successive calls Torque makes to the scheduler (see Section 3.4.15, “Torque”).
Since the period character has a special meaning to the ganglia plugin, it is recommended to avoid using this character elsewhere, for example, within torque group names. Although there are no problems with sending the resulting metrics, it introduces a source of potential confusion.
Avoiding metric loss
Ganglia uses multicast UDP traffic for metric updates, which is
unreliable protocol. Unlike the reliable TCP protocol, UDP
has no mechanisms for detecting if a packet was not delivered or
for retransmitting missing data. However, over local area
networks it is very unlikely that the network packets will be
lost.
If a large number of metrics are updated at the same time, there is a corresponding deluge of packets. If these packets are delivered too quickly, the recipient gmond process may not be able to keep up. Those packets not accepted immediately by gmond will be held in a backlog queue, allowing gmond to process them when free. However, if the size of this backlog queue exceeds a threshold, further packets will not be queued and gmond will not see the corresponding metric update messages. The threshold varies, but observed values are in the range 220–450 packets.
To reduce the risk of metric updates being lost, the MonAMI ganglia plugin will pause after delivering a multiple of 50 metric updates. By default the pause is 100 ms, but the delivery_pause attribute can be used to fine-tune this behaviour. Under normal circumstances, the default delivery_pause value results in a negligible risk of metric updates being lost. However, if the machine receiving the metrics is under heavy load you may notice metrics being dropped.
To further reduce the risk of metric update loss, monitoring
activity can be split into separate activities that are triggered
at different times. In the following example, two monitoring
targets (torque and maui) are sampled
every minute with all metrics sent to Ganglia.
[torque] cache = 60 [maui] cache = 60 [sample] interval = 1m read = torque, maui write = ganglia [ganglia]
If the resulting datatree has too many metrics there will be a risk that some of metric updates will be lost. To reduce the risk of this, the same monitoring can be achieved by splitting the activity into two parts. The following example shows the same monitoring but split into two independent activities. Both monitoring targets are monitored every minute but now at different times.
[torque] cache = 60 [maui] cache = 60 [sample] interval = 1m read = torque write = ganglia [sample] interval = 1m read = maui write = ganglia [ganglia]
An alternative approach is to increase the UDP packet buffer size. Increasing the buffer size will allow more packets to be queued before metric updates are lost. The following set of commands, run as root, will restart gmond with a larger network receive buffer (N.B. the hash character represents the prompt and should not be typed).
# orig_default=$(cat /proc/sys/core/rmem_default) # cat /proc/sys/net/core/rmem_max > /proc/sys/net/core/rmem_default # service gmond restart # echo $orig_default > /proc/sys/net/core/rmem_default
Another method of setting rmem_default is to use the
/etc/sysctl.conf file. A sample entry is
given below:
# Enlarge the value of rmem_default for gmond. Be sure to check the # number against /proc/sys/net/core/rmem_max. net.core.rmem_default=131071
dmax
Each metric has a corresponding dmax value. This value specifies when Ganglia should consider the metric as no longer being monitored. If a metric has not been updated for dmax seconds Ganglia will remove it. Graphs showing historical data are not purged; however, when delivery of the metric resumes there may be a corresponding gap in the historical data.
As a special case, if a metric's dmax value is set to zero, Ganglia will never purge that metric. Should MonAMI stop updating that metric, its last value will be graphed indefinitely, or until either MonAMI resumes sending fresh data or the metric is flushed manually (by restarting the gmond daemon).
The optimal value of dmax is a compromise. If the value is set too low then an unusually long delay whilst gathering data might trigger the metric being purged. If set too high, then Ganglia will take longer than necessary to notice if MonAMI has stopped sending data.
When updating a metric, a fresh value of dmax is also sent. This allows MonAMI to adjust the dmax value over time. For event-driven data the default value is zero, effectively disabling the automatic removal of data. With internally triggered data (e.g., data collected using a sample target), the value of dmax is calculated taking into account when next data is scheduled to be taken and an estimate of how long that data acquisition will take. Section 3.3.4, “Estimating future data-gathering delays” describes how MonAMI estimates the delay in future data-gathering.
Calculating a good value of dmax also requires knowledge of the
gmetad polling interval: the time between successive gmetad
requests to gmond. This is specified in the gmetad
configuration file (usually either
/etc/gmetad.conf or
/etc/ganglia/gmetad.conf). Each
data_source line has an optional polling interval
value, expressed in seconds. If the polling interval is not
specified, gmetad will use 15 seconds as a default value.
In general, the MonAMI ganglia plugin cannot discovering the gmetad polling interval automatically. Instead, the dmax calculation assumes the polling interval is less than two minutes. This is very likely to be sufficient; but, should the gmetad polling interval be longer than two minutes, the correct value can be specified (in seconds) using the gmetad_poll attribute.
Separate from estimating a good value of dmax, an explicit dmax value can be specified using the dmax attribute. For example, setting the dmax attribute to zero will set all metric update's dmax values to zero unconditionally, so preventing Ganglia from purging any metric.
It is recommended that the default value of dmax is used. If long gmetad polling intervals are in use, include a suitable gmetad_poll attribute.
Multiframe extension
Ganglia's standard web interface provides a good overview of the metrics supplied by gmond, but for other metrics are displayed either as a single graph or not at all.
To provide a rich view of the data MonAMI collects, an extension to the standard web interface has been developed. This supports creating tables, custom graphs and pie-charts, support for iGoogle and embedding elements within other pages.
The multiframe extension is currently maintained within the external CVS module. Instructions on how to install and extend these graphs are available within that module.
Attributes
- multicast_ip_address string, optional
the multicast IP address to which the data should be sent. If no IP address is specified, the Ganglia default value of
239.2.11.71is used.- multicast_port integer, optional
the port to which the multicast traffic is sent. If no port is specified, the Ganglia default port of 8649 is used.
- host string, optional
The
IPaddress of the host to whichUDPunicast traffic should be sent. Specifying this option will switch off sending metrics as multicast. The default is not to send unicast traffic, but to send multicast traffic.- port integer, optional
the
UDPport to which unicast traffic should be sent. If host is specified and port is not then the default port is used. If host is not specified, then port has no effect.- multicast_if string, optional
the network device through which multicast traffic should be sent (e.g., “eth1”). If no device is specified, a default is chosen by the kernel. This default is usually sufficient.
- config string, optional
the non-standard location of a gmond configuration file.
- gmetad_poll integer, optional
the polling interval of gmetad in seconds. This is the time between successive gmetad requests to gmond. By default, the plugin assumes this is two minutes or less. If this is wrong, the correct value is specified using this attribute.
- dmax integer, optional
the absolute period, in seconds, after the last metric update after which Ganglia should remove that metric. A value of zero disables this automatic purging of metrics. By default, the plugin will estimate a suitable value based on observer behaviour when gathering data.
- delivery_pause integer, optional
the delay in milliseconds between an exact multiple of 50 and the following metric update. Every 50 UDP packets, the plugin will pause briefly. The default (100 ms) is an empirical value that should be sufficient. The minimum and maximum values are 5 ms and 2000 ms.
GridView is a Worldwide LHC Computational Grid (WLCG) project that provides centralised monitoring for the WLCG collaboration. It collates information from multiple sources, including R-GMA and MonaLisa, and displays this aggregated information. In addition to accumulated data, it can accept data sent directly via a web-service, which is how this reporting plugin works. The protocol allows arbitrary data to be uploaded. Live data and further details are available from the GridView homepage.
The gridview plugin implements the GridView protocol, allowing data to be uploaded directly into GridView. Each datatree sent is directed towards a particular table, as described by the table attribute. The table name is arbitrary and describes the nature of the data and contains one or more fields. The number of fields and each of the fields type is table-specific.
The send attribute is a comma-separated
list of which data, and in what order data is to be sent. Each
element of the list is the name of some element within a datatree;
elements are separated by a dot (.). Should any of
the elements be missing, the corresponding field sent to GridView
will be blank.
Attributes
- table string, required
the name of the table within GridView to populate with data.
- send string, required
the comma-separated list of data to send: one entry for each field. The data should be a path within a datatree using a dot (
.) as the separator between names within the datatree.- endpoint string, optional
the SOAP endpoint to which MonAMI should contact. The default endpoint is
http://grvw003.cern.ch:8080/wsarch/services/WebArchiverAdv
Gr_Monitor is an application that uses the OpenGL API to display monitoring information as a series of animated 3D bar charts. More information is available from the Gr_Monitor home page.

Gr_Monitor uses a flexible XML format for data exchange. This allows it to receive data from a variety of helper applications, each of which collect information from different sources. Further custom applications allow easy expansion of gr_Monitor's capabilities.
Recent versions of gr_Monitor provide the facility to receive this
XML data from the network (through a TCP connection). The
MonAMI grmonitor plugin provides a network socket that
the gr_Monitor application can connect to. To connect gr_Monitor
to MonAMI, use the -tcp option:
gr_monitor -tcp
hostname:port
The option hostname
should be replaced with the hostname of the MonAMI daemon (e.g.,
localhost) and port
should be replaced by whatever TCP port number MonAMI is
listening on (50007 by default).
Metrics from a datatree are mapped to positions within groups of 3D bar charts, which gr_Monitor then plots. To configure this mapping, the grmonitor plugin expects at least one of each of the following attribute: group, metric, metricval, and either item or itemlist. All of the attributes may be repeated.
A group is a rectangular collection of metrics, usually with a common theme; for example, in Figure 3.3, “gr_Monitor showing data from apache and mysql targets” there are two groups: one shows Apache thread status, the other shows per-table metrics for a MySQL database. Each group has a label or title and is displayed as a distinct block in the 3D display. In the MonAMI configuration, group attribute values have a local-name for the group, a colon, then the display label for this group. The group local-name is used when defining how the group should look and the label is passed to gr_Monitor to be displayed.
The item attribute describes a specific column within a group. Typically, each item describes one of a list of things; for example, one filesystem of several mounted, a queue within the set of batch-system queues, a table within the many a database stores. The item values have the group short-name, a comma, an item short-name, a colon, then the display label for this item. An item short-name is used to identify this item and the display label is passed on to gr_Monitor.
A metric attribute describes a generic measurable aspect of the items within a group; e.g., used capacity and free capacity (for filesystems), or number of jobs in running state and number in queued state for a batch system. The metric correspond to the rows of related information shown in Figure 3.3, “gr_Monitor showing data from apache and mysql targets”. The metric values have the form group short-name, comma, metric short-name, colon, then the label. The metric short-name is used to identify this metric and the label is passed on to gr_Monitor as the label it should display for this row.
The final required attribute type is metricval. The metricval attributes map the incoming datatree to bars within the 3D bar-chart. There should be a metricval for each (item,metric) pair in each group. metricval attribute values have a comma-separated list of group, item and metric short-names, a colon, then the datatree path for the corresponding MonAMI metric.
The following example demonstrates configuring a grmonitor target. It defines a single group “Torque queue info” with three items (columns) “Atlas”, “CMS” and “LHCb”. Each item has two metric attributes: “Running” and “Queued”. The metricval attributes map an incoming datatree to these values.
[grmonitor]
group = g1 : Torque queue info
metric = g1, m_running : Running
metric = g1, m_queued : Queued
item = g1,i_atlas : Atlas
item = g1,i_cms : CMS
item = g1,i_lhcb : LHCb
metricval = g1,i_atlas, m_running: \
torque.Queues.Execution.ByQueue.atlas.Jobs.State.running
metricval = g1,i_atlas, m_queued: \
torque.Queues.Execution.ByQueue.atlas.Jobs.State.queued
metricval = g1,i_cms, m_running: \
torque.Queues.Execution.ByQueue.biomed.Jobs.State.running
metricval = g1,i_cms, m_queued: \
torque.Queues.Execution.ByQueue.biomed.Jobs.State.queued
metricval = g1,i_lhcb, m_running: \
torque.Queues.Execution.ByQueue.lhcb.Jobs.State.running
metricval = g1,i_lhcb, m_queued: \
torque.Queues.Execution.ByQueue.lhcb.Jobs.State.queuedUsing itemlist
Writing out all metricval attributes can be quite tiresome and error prone. The data provided by a datatree might also change over time, perhaps dynamically whilst MonAMI is running. For these reasons, MonAMI supports an express method of describing the mapping, which uses the itemlist attribute. This makes the mapping more dynamic and its description more compact.
The itemlist replaces the need for specifying item attributes explicitly. A group should have at least one item or itemlist otherwise no data would be plotted.
The itemlist attribute is similar to an item but, instead of specifying the label, the value after the colon specifies a branch of the datatree. Specifying an itemlist also affects how metricval attributes are interpreted.
When a new datatree is received, the grmonitor target
will look for the specified branch and will consider each child
entry as an item. For example, if the incoming datatree has a
branch aa.bb with two child branches
aa.bb.item1 and aa.bb.item2, specifying
an itemlist attribute with
aa.bb is equivalent to specifying two
items labelled “item1” and
“item2”. This is most useful when the indicated
branch contains a list of similar items.
The metric attributes are as before; they provide the graphical labels for the metrics. There must be a metric value for each row within the group.
The metricval attributes describe the path
within the datatree to the desired metric, relative to the item's
branch. If the itemlist specifies a path
aa.bb and the metricval
specifies xx.yy, then values will be plotted for:
aa.bb.item1.xx.yy (labelled “item1”),
aa.bb.item2.xx.yy (labelled “item2”),
etc. These must be valid metrics or they will be ignored.
metricval attributes may take a special
value: a single dot. This indicates that the immediate children
of the itemlist path should be plotted
directly. For example, if an itemlist
attribute has a value of aa.bb and
metricval is . then values
will be plotted for aa.bb.item1 (as
“item1”), aa.bb.item2 (as
“item2”), and so on. A
metricval with a dot will only plot metrics
if the items immediately below the itemval branch are metrics,
branches will be ignored.
The following example demonstrates itemlist and illustrates using both metricval to point to metrics and the special dot value. It creates two groups: one that plots the number of Apache thread in each state (for details, see Section 3.4.2, “Apache”) and another that plots three metrics from MySQL (see Section 3.4.8, “MySQL”). The MySQL group plots three table-specific metrics for all tables in the mysql database. This is the configuration that produced the output shown above in Figure 3.3, “gr_Monitor showing data from apache and mysql targets”.
[grmonitor] group = gApache : Apache itemlist = gApache, iThreadState : apache.Threads metric = gApache, mCount : Count metricval = gApache, iThreadState, mCount : . group = gMysql : MySQL (mysql database) metric = gMysql, mCurLen : Length metric = gMysql, mIdxLen : Idx length metric = gMysql, mRows : Rows itemlist = gMysql, iDbMysql: mysql.Database.mysql.Table metricval = gMysql, iDbMysql, mCurLen : Datafile.current metricval = gMysql, iDbMysql, mIdxLen : Indexfile.length metricval = gMysql, iDbMysql, mRows : Rows.count
Attributes
- port integer, optional
the network port on which the plugin will listen. If not specified, then the default (50007) is used.
- group string, at least one
defines a rectangular set of data results, forming a 3D bar chart. Attribute values have the form
group name:group label- metric string, at least one per group
hold information about a row of data within a group. Attribute values have the form
group name,metric name:metric label- item string, at least one per group (if there are no itemlist attributes)
describes a column of data within a group. Attribute values have the form
group name,item name:item label- itemlist string, at least one per group (if there are not item attributes)
describes a set of columns of data within a group, by specifying a branch within the incoming datatree. The immediate child of this branch are considered part a list of items.
Attribute values have the form
group name,item name:branch path- metricval string, one per (group,metric,item)
Definition of which MonAMI metric maps to a particular location within a group. Attributes values have the form
group name,item name,metric name:metric path
KSysGuard is a default component of the KDE desktop environment.
It is designed for monitoring computers and separates monitoring
into two distinct activities: gathering information and presenting
it to the user. Displaying information is achieved with a GUI
program KSysGuard (written using the KDE framework) whilst
gathering data is handled by a small program, ksysguardd, that
can run as a remote daemon. The ksysguard MonAMI plugin
emulates the ksysguardd program, allowing KSysGuard to
retrieve information.
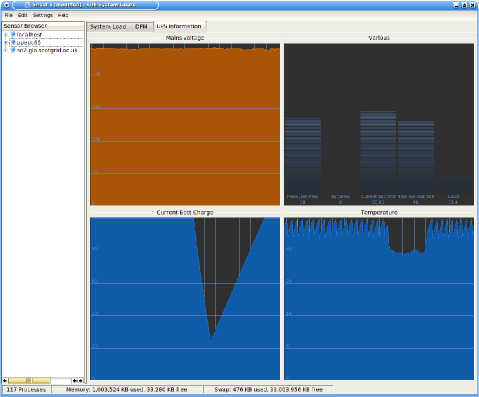
KSysGuard supports a variety of display-types (different ways of displaying sensor data). Some of these display-types allow data from multiple sensors to be combined. Worksheets (panels with a grid of different displays) are easily updated using drag-and-drop and can be saved for later recall.
KSysGuard and ksysguardd communicate via a documented
stream-protocol. Typical default usage has ksysguardd started
automatically on the local machine, with communication over the
process' stdout and stderr file-handles.
Collecting data from remote machines is supported by KSysGuard
either via ssh or using direct TCP communication. With the
ssh method, the GUI establishes an ssh connection to the
remote machine and executes ksysguardd (data is transfered
through ssh's tunnelling of stdout and stderr). With the
TCP method, KSysGuard establishes a connection to an existing
ksysguardd instance that is running in network-daemon mode.
The MonAMI ksysguard plugin implements the KSysGuard
stream-protocol and acts like ksysguardd running as a daemon.
By default, it listens on port 3112 (ksysguardd's default port)
and accepts only local connections. A more liberal access policy
can be configured by specifying one or more
allow attributes.
Note
Older versions of ksysguard contained a bug that was triggered by a sensor name containing spaces. This was fixed in KDE v3.5.6 or later.
To view the data provided by MonAMI within KSysGuard, select → , which will open a dialogue box. Enter the hostname of the machine MonAMI is running on in the Host input and make sure the Connection Type is set to Daemon. You should see the host's name appear within the sensor-browser tree (on the left of the window). Expanding the hostname will trigger KSysGuard to query MonAMI for the list of available metrics. If this list is long, it can take a while for KSysGuard to parse the list.
More details on how to use KSysGuard can be found in the KSysGuard Handbook.
Within MonAMI, the ksysguard target configured must specify a target from which the data is requested (via the read parameter). This source can be either an explicit monitoring plugin (e.g., using a target from the apache plugin) or a named sample target. The named sample can either act solely as an aggregator for KSysGuard (i.e., with no write or interval specified) or can be part of some other monitoring activity. See Section 3.6, “sample” for more information on sample targets.
The following example shows the ksysguard plugin directly
monitoring an Apache server running on
www.example.org
[apache]
host = www.example.org
[ksysguard]
read = apacheThe following example demonstrates how to use a named-sample to monitor multiple monitoring targets with KSysGuard.
[apache] name = external-server host = www.example.org [mysql] name = external-mysql host = mysql-serv.example.org user = monami password = monami-secret cache = 10 [apache] name = internal-server host = www.intranet.example.org [mysql] name = internal-mysql host = mysql-serv.intranet.example.org user = monami password = monami-secret cache = 10 [sample] name = ksysguard-info read = external-server, external-mysql, internal-server, internal-mysql [ksysguard] read = ksysguard-info
Attributes
- read string, required
the name of the target from which data is to be requested
- port integer, optional
the port on which the ksysguard target will listen for connections. If no port is specified, then 3112 will use, the default for
ksysguardd.- allow string, optional
a host or subnet from which this plugin will accept connections. This can be specified as a simple hostname (e.g.,
mydesktop), a fully qualified domain name (e.g.,www.example.com), an IPv4 address (e.g.,10.1.0.28), an IPv4 address with a netmask (e.g.10.1.0.0/255.255.255.0) or an IPv4 subnet using CIDR notation (e.g.,10.1.0.0/24).The plugin will always accept connections from
localhostand from the host's fully qualified domain name.This attribute can be repeated to describe all necessary authorised hosts or networks.
This plugin pushes information gathered by MonAMI into the
MonALISA monitoring system (MonALISA home
page). It does this by sending the data
within a UDP packet to a MonALISA-Service (ML-Service) server.
ML-Service is a component of MonALISA that can be located either
on the local site or centrally.
Within the MonALISA (ML) hierarchy, a cluster contains one or more nodes (computers). These clusters are grouped together into one or more farms. Farms are handled by MonALISA-Services (ML-Services), usually a single farm per ML-Service. The ML-Service is a daemon that is responsible for collecting monitoring data, and providing both a temporary store for that data and a means by which that data can be acquired.
Clients query the data provided by ML-Services via transparent proxies. There are also LookUp Services (LUSs) that contain soft-state registrations of the proxies and ML-Services. The LUSs provide a mechanism by which client requests are load-balanced across different proxies and dynamic data discovery can happen.
The ML-Services acquire data through a number of MonALISA plugins. One such plugin is XDRUDP, which allows nodes to send arbitrary data to the ML-Service. The MonALISA team provide an API for sending this data called ApMon. It is through the XDRUDP ML-plugin that MonAMI is able to send gathered data.

Note that each MonAMI monalisa target reports to a specific host, port, cluster triple. If you wish to report data to multiple ML-Services or to multiple ML clusters, you must have multiple MonAMI monalisa targets configured: one for each host or cluster.
Attributes
- host string, optional
the hostname of the ML-Service. The default value is
localhost.- port integer, optional
the port on which the ML-Service listens. The default value is 8884.
- password string, optional
the password to access the MonAlisa service.
Warning
The password is sent plain-text: don't share a sensitive password with MonALISA! By default, no password is sent.
- apmon_version string, optional
the plugin reports “2.2.0” as an ApMon version string by default. This option allows you report a different version.
- cluster string, required
the cluster name to report.
- node string, optional
the node name to report. There are two special cases: if the literal string
IPis used, then MonAMI will detect the IP address and use that value; if the literal stringFQDNis used, then MonAMI will determine the machine's Fully Qualified Domain Name and use that. The default is to report the machine's FQDN.
In addition to monitoring a MySQL server, the mysql plugin can also append monitoring data into a table. If correctly configured, each datatree the plugin receives will be stored as a new row within a specified table.
The two MySQL operations (monitoring and storing results) are not mutually exclusive. A mysql target can be configured to both store data and also to monitoring the MySQL server it is contacting.
Two attributes are required when using the mysql plugin for storing results: database and table. These specify into which MySQL database and table data is to be stored.
If the database named in the database attribute does not exist, no attempt is made to create it. This will prevent MonAMI from storing any data.
If the table does not exist, the plugin will attempt to create it when it receives data. The plugin determins the types for each field from the field's corresponding metric. If, when creating the table, a field attribute has no corresponding metric within the incoming datatree, the corresponding field within the database table is created as TEXT.
Privileges
In order to insert data, the MySQL user the plugin authenticates as must have been granted sufficient privileges. Additional privileges are needed if you wish to allow the plugin to create missing tables as needed.
The following SQL commands describes how to create a database
mon_db, create a MySQL user account
monami with password
monami-secret
CREATE USER 'monami' IDENTIFIED BY 'monami-secret'; CREATE DATABASE mon_db; GRANT CREATE,INSERT ON mon_db.* TOmonami;
A lightly more secure, but more awkward solution is to manually
create the storage tables. The following SQL commands describe
how to create a database mon_db, create an
example table roomstats, create
a MySQL user account monami
with password monami-secret, and grant that user
sufficient privileges to insert data only for that table.
CREATE USER 'monami' IDENTIFIED BY 'monami-secret'; CREATE DATABASE mon_db; CREATE TABLE roomstats ( collected TIMESTAMP, temperature FLOAT, humidity FLOAT, aircon1good BOOLEAN, aircon2good BOOLEAN); GRANT INSERT ON mon_db.roomstats TOmonami;
Fields
One must describe how to fill in each of the table's fields. To do this, the configuration should include several field attributes, one for each column of the table.
A field attribute value has the form:
field : metric pathfieldmetric
path
The collected field
The collected field is a special case. It stores the timestamp of when the datatree data was obtained. The table must have a column with this name with type TIMESTAMP. This field is filled in automatically: there is no need for a field attribute to describe the collected field.
The following example shows a suitable configuration for storing gathered data within the above room_stats table. The datatree is fictitious and purely illustrative.
[mysql] user =monamipassword =monami-secretdatabase = mon_db table = room_stats field = temperature : probes.probe1.temperature field = humidity : probes.probe1.humidity field = aircon1good : aircons.aircon1.good field = aircon2good : aircons.aircon2.good
Attributes
- host string, optional
the host on which the MySQL server is running. If no host is specified, the default
localhostis used.- user string, required
the username with which to log into the server.
- password string, required
the password with which to log into the server
- database string, required
the database in which the storage table is found. If this database does not exist then no data can be stored.
- table string, required
the table into which data is stored. If the table does not exist, it is created automatically.
- field string, at least one
a mapping between a metric from a datatree and a database field name. This attribute should be specified for each table column and has the form
field:datatree path
Nagios is a monitoring system that provides sophisticated service-status monitoring: whether a service's status is OK, Warning or Critical. Its strengths include support for escalation and flexible support for notification and potentially automated service recovery. A complete description of Nagios is available at the Nagios home page.
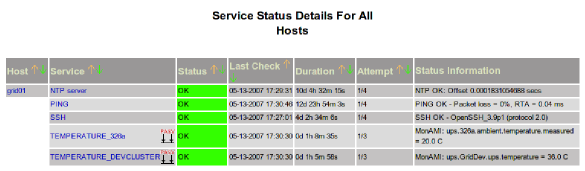
The Nagios monitoring architecture has a single Nagios central server. This Nagios server maintains the current status of all monitored hosts and the services offered by those hosts. It is the central Nagios server that maintains a webpage front-end and that responds to status changes. For remote hosts, Nagios offers two methods of receiving status updates: active and passive.
Active queries are where the Nagios server initiates a connection to the remote server, requests information, then processes the result. This requires a daemon (npre) to be running and a sufficient subset of the monitoring scripts to be installed on the remote machine.
With passive queries, the remote site sends status updates to the Nagios server, either periodically or triggered by some event. To receive these messages, the Nagios server must either run the nsca program as a daemon, or run a inetd-like daemon to run nsca on-demand.
Caution
There is a bug in some versions of the nsca program. When triggered, nsca will go into a tight-loop, so preventing updates and consuming CPU. This bug was fixed with version 2.7.2. Make sure you have at least this version installed.
MonAMI will send status information to the Nagios server. This follows the passive query usage, so nsca must be working for Nagios to accept data from MonAMI.
Nagios and nsca
This section gives a brief overview of how to configure Nagios to accept passive monitoring results as provided by nsca. Active monitoring is the default mode of operation and often Nagios is deployed with passive monitoring disabled. Several steps may be required to enable it. The information here should be read in conjunction with the Nagios documentation. Also, if nsca is packaged separately, make sure the package is installed.
Location of Nagios configuration
The Nagios configuration files are located either in /etc or, with more recent packages,
in /etc/nagios. It is
also possible that they may be stored elsewhere, depending on
the local installation. For this reason, when Nagios
configuration files are mentioned, just their base name will be
given rather than the full path.
To run nsca as part of an xinetd make sure there is a suitable
xinetd configuration file (usually located in /etc/xinetd.d). Some packages also
include suitable configuration for xinetd, but usually disabled
by default. To enable nsca, make sure the disabled
field within the nsca's xinetd-configuration file is set to
no and restart xinetd.
To run nsca as part of inetd, add a suitable line to the
inetd configuration file /etc/inetd.conf
and restart inetd.
To run nsca as a daemon, independent of any inetd-like
service, make sure no inetd-like service has adopted nsca
(e.g., set disabled in the corresponding xinetd
configuration file to yes, or comment-out the line in
inetd configuration) and start nsca as a daemon (e.g.,
service nsca start).
Passive monitoring requires that Nagios support external commands.
The packaged default configuration may have this switched off. To
enable external commands, make sure the
check_external_commands parameter is set to
1. This option is usually located in the main
configuration file, nagios.cfg. Nagios will
need to be restarted for this to have an effect.
Make sure Nagios can create the external command socket. The
default location is within the /var/log/nagios/rw directory. You
may need to change the owner of that directory to the user the
Nagios daemon uses (typically nagios).
If there are problems with communication between MonAMI and
nsca, the nsca debugging option can be useful. Debugging is
enabled by setting debug=1 in the nsca
configuration file: nsca.cfg. The debug
output is sent to syslog, so which file the information can be
found in will depend on the syslog configuration. Typically, the
output will appear in either
/var/log/messages or
/var/log/daemon.
Adding passive services to Nagios
Nagios only accepts passive monitoring results for services it knows about. This section describes how to add additional service definitions to Nagios so MonAMI can provide status information.
Nagios supports templates within its configuration files. These allow for a set of default service values. If a service inherits a template, then the template values will be used unless overwritten. The following section gives a suitable template for a MonAMI service; you may wish to change these values to better suite your environment.
define service {
name monami-service
use generic-service
active_checks_enabled 0
passive_checks_enabled 1
register 0
check_command check_monami_dummy
notification_interval 240
notification_period 24x7
notification_options c,r
check_period 24x7
contact_groups monami-admins
max_check_attempts 3
normal_check_interval 5
retry_check_interval 1
}
Note how the active checks are disabled, but passive checks are
allowed. Also, the contact_groups has been set to
monami-admins. Either this contact group must be
defined, or a valid group be substituted.
In the above template, a check_command was specified.
Nagios requires this value to be set, but as active checks are
disabled, any valid command will do. To keep things obvious, we
use the explicit check_monami_dummy command. The
following definition is valid and can be placed either in
commands.cfg or in some local collection of
extra commands.
define command {
command_name check_monami_dummy
command_line /bin/true
}
The final step is to add the services Nagios is to accept status
information. These definitions will allow MonAMI to upload status
information. The definitions should go within one of the Nagios
configuration files mentioned by cfg_file= in
nagios.cfg.
The following two examples configure specific checks for a named host.
define service {
use monami-service
host_name grid01
service_description TOMCAT_WEB_THREADS_CURRENT
}
define service {
use monami-service
host_name grid01
service_description TOMCAT_WEB_THREADS_INUSE
}The following example shows a service check defined for a group of hosts. Hosts acquire the service check based on their membership of the hostgroup. This is often more convenient when several machines are running the same service.
define hostgroup {
hostgroup_name DPM_pool_nodes
alias All DPM pool nodes.
members disk001, disk002, disk003, disk005, disk013
}
define service{
use monami-service
hostgroup_name DPM_pool_nodes
service_description DPM_free_space
}Configuring MonAMI
To allow MonAMI to report the current state of various services, one must configure a nagios reporting target. This describes both the machine to which MonAMI should connect, and the services that should be reported.
The host attribute describes the remote
host to which status information should be sent. If no host is
specified, MonAMI will attempt to contact nsca running on the
machine on which it is running (localhost). The
port attribute describes on which TCP
port the nsca program is listening. If no
port is specified, then the nsca default
port is used.
To be useful, each nagios target must define at least one
service. Each service must have a corresponding definition within
Nagios (as described above), else Nagios will ignore the
information. To define a service, the
service attribute is specified. The
service values have the following form:
short name :
Nagios name
short namea simple name used to associate the service with the various check attributes.
Nagios namethe name of the service within Nagios. This is the
service_descriptionfield (as shown above). It is also the name the Nagios web interface will show.
Two example service definitions are given below. A nagios target can have an arbitrary number of definitions.
service = tcat-threads, TOMCAT_WEB_THREADS_INUSE service = tcat-process, TOMCAT_PROCESS
Given a service definition, one or more
check attributes must be defined. The
checks determine the status (OK, Warning or
Critical) of a service. The check values
have the following form:
short name :
data source,
warn value,
crit value
These fields have the following meaning:
short namethe short name from the corresponding service definition.
data soucethe path within a datatree to the metric under consideration.
warn valuethe first value that metric can adopt where the check is considered in Warning status.
crit valuethe first value that metric can adopt where the check is considered in Critical status.
When multiple check attributes are defined for a service, all the checks are evaluated and the service adopts the most severe status. In order of increasing severity, the different status are OK, Unknown, Warning Critical.
Examples of MonAMI configuration
The following is an example of a complete definition. A single service is defined that has a single check, based on output from the nut plugin (see Section 3.4.10, “NUT”.
[nagios] service = ups-temp, Temperature check = ups-temp, nut.myups.ups.temperature, 25, 35
The status of Temperature depends on
nut.apc3000.ups.temperature. If it is strictly less
than 25 Temperature has status OK. If 25 or more,
but strictly less than 34 it has status Warning and if 35 or
greater it has status Critical.
Another example, again using output from the nut plugin.
[nagios] service = ups-volt, Mains check = ups-volt, nut.myups.input.voltage.instantaneous, 260, 280 check = ups-volt, nut.myups.input.voltage.instantaneous, 210, 190
The Mains service is OK if the mains voltage lies
between 210 V and 260 V, between 190 V and
210 V or between 260 V and 280 V its Warning and
either less than 190 V or greater than 280 V its
considered Critical.
Attributes
- host string, optional
the hostname to which the reporting plugin should connect. The default value is
localhost.- port integer, optional
the port to which the plugin should connect. The default value is 5667, the default for nsca.
- password string, optional
the password used for this connection. Defaults to not using a password.
- service string, optional
defines a service that is to be reported to Nagios. The format is
short name:Nagios name- check string, optional
defines a check for some service. A check is something that can affect the status of the reported service. The format is
short name:data source,warning value,critical value- localhost string, optional
defines the name the nagios plugin reports for itself when sending updates. By default, the plugin will use the FQDN. Specify this attribute if this is incorrect.
In addition to providing data (albeit, an empty datatree), the null plugin can also act as a reporting plugin, but one that will discard any incoming data.
A null target will act as an information sink, allowing monitoring activity to continue without the information being sent anywhere.
Attributes
The null plugin, used as a writer, does not accept any attributes.
The Service Availability Monitoring (SAM) is an in-production service monitoring system based in CERN. The GOC Wiki describes SAM further. Also available is a webpage describing the latest results.
The sam plugin allows information to be sent to a SAM monitoring host based on the methods described in the GOC Wiki.
Note
This module will have no effect unless the tests are registered prior to running the code.
The CERN server is firewalled, so running tests may not result in immediate success.
This is work-in-progress.
Attributes
- VO string, required
the VO name to include with reports.
- table string, required
the name of the table into which the data is to be added.
- node string, optional
the node name to report. This defaults to the machine's FQDN.
- endpoint string, optional
the end-point to which the reports should be sent. This defaults to
http://gvdev.cern.ch:8080/gridview/services/WebArchiver
The snapshot reporting plugin stores a representation of the last datatree it received in a file. Unlike the filelog plugin, snapshot provides no history information; instead, it provides a greater depth of information about the last datatree it received.
Attributes
- filename string, required
the filename of the file into which the last datatree is stored.
R-GMA (Relational Grid Monitoring Architecture) is an information system that allows data to be aggregated between many sites. It is based on the Open Grid Forum (formerly Global Grid Forum) architecture for monitoring, Grid Monitoring Architecture. R-GMA uses a Producer-Consumer model, with a Registry to which all producers register themselves periodically. Interactions with R-GMA are through a subset of SQL. Further information on R-GMA is available from the R-GMA project page and the R-GMA in 5 minutes document.
A typical deloyment has a single R-GMA server per site (within WLCG, this is the MON box). Within the R-GMA architecture, the producers are located within this R-GMA server. Local data is submitted to the R-GMA server and held there. External R-GMA clients (R-GMA Consumers) contact the R-GMA Producers to query the gathered data.
Locating the server
The rgma plugin allows MonAMI to upload data to an R-GMA server. Often this will not be the same machine on which MonAMI is running, so MonAMI must either discover the location of the server or use information in its configuration.
If the machine on which MonAMI is running has a properly installed
R-GMA environment, it will have a file
rgma.conf that states which machine is the
R-GMA server and details on how to send the data. Unfortunately,
this file can be located in many different locations, so its
location must be discovered too.
If the rgma_home attribute is specified,
MonAMI will try to read the R-GMA configuration file
rgma_home/etc/rgma/rgma.conf
If the rgma_home attribute is not
specified, or does not locate a valid R-GMA configuration file,
several environment variables are checked to see if they can
locate a valid R-GMA configuration file. MonAMI will tries the
environment variables RGMA_HOME,
GLITE_LOCATION and EDG_LOCATION,
each time trying to load the file
VAR/etc/rgma/rgma.conf.
If neither the rgma_home attribute nor any
of the environment variables, if specified, can locate the
rgma.conf file, a couple of standard
locations are tried. MonAMI will try to load /opt/glite/etc/rgma/rgma.conf and
/opt/edg/etc/rgma/rgma.conf.
If the file rgma.conf does not exist, the
host and TCP port of the R-GMA server may be specified
explicitly within the configuration file. The attributes
host, port and
access state to which host, on which port
and how securely the connection should be made. Usually
specifying just the host is sufficient.
In summary, to allow the rgma plugin to work, you must satisfy one of the following:
have a valid
rgma.conffile in one of its standard locations (/opt/glite/etc/rgma/or/opt/edg/etc/rgma/), ormake sure the MonAMI process has the correct
RGMA_HOME,GLITE_LOCATIONorEDG_LOCATIONenvironment variable set, orspecify the rgma_home attribute, locating the
rgma.conffile, orexplicitly set one or more of the following attributes: host, port, access, or
run MonAMI on the same machine as the R-GMA server.
Sending data
The R-GMA system resembles a relational database with data separated into different tables. Each table may have many columns, with data being supplied to any or all of those columns with one set of data.
Each rgma target delivers data to a single R-GMA table.
The table name must be specified and is given by the
table attribute. How data is delivered
within that table is defined by column
attributes. Each column attribute defines
a mapping between some metric within a datatree and an R-GMA
column name. The value of a column
attribute has the form
R-GMA column :
metric name
[option,
option]metric nametransfer.size in the
datatree to the R-GMA column size.
column = size : transfer.size
The optional square brackets within the column attribute values contain options that adjust rgma's behaviour for this data. These options are a comma separated list of keyword,value pairs, where the following keywords are available:
maxsizeThe maximum length of a string metric. If a string metric would be too long for this column, it is truncated so the last five characters are
[...].
The following example configures MonAMI to send a string metric that is never longer than 255 characters; a string will be truncated if it is longer.
column = filename : downloaded.filename [maxsize = 255]
R-GMA query types
R-GMA supports four types of query: continuous, history, latest and static.
A continuous query of a table will return data whenever it is inserted into that table. All matching data added to R-GMA will appear in a continuous query. It is possible to issue a continuous query that includes all old data before waiting for new data. Although this will return historic data, there is no guarantee for how long the R-GMA server will retain the data.
A reliable archive of the recent history of measurements or events is possible. A history query will return all matching data still present, but with a defined retention policy. To be a candidate for history queries, data must be marked for historic queries when it is inserted into a table. Any data not marked will be ignored by history queries.
R-GMA also understands the concept of the “latest” result. An R-GMA latest query selects the most recent measurement. However, to be considered, data must be marked as a candidate for latest queries when added. Any data that is not so marked is ignored.
A static query is a query that uses R-GMA's support for on-demand monitoring. Currently, rgma has no support for this query type.
When adding data, MonAMI will mark whether it should be considered for latest or historical queries (or both). This is controlled by the type attribute, a comma-separated list of query-types for which the data should be a candidate.
Data will always appear in continuous queries. By default, that
is the only query type data will appear in. If the
type list contains history
then data is marked for history queries and will also show up in
history queries. If it contains latest then it will
also show up in R-GMA latest queries.
Storage and retention of data
Data can be stored on the R-GMA server in one of two locations:
either in memory or within a database. By default, data is stored
in memory; however, the MonAMI storage
attribute can specify where R-GMA will store data. The valid
values are memory and database (for
storing in memory and within a database, respectively).
Note
The current implementations of R-GMA support history- and latest- queries only when data is stored within a database.
In general, data will be retained within R-GMA for some period. How long data is retained depends on several factors. If the data is neither marked for history nor latest queries then the retention period is not guaranteed.
The latest retention period is how long data is kept if it is marked for latest queries. R-GMA makes no guarantee to expunge the data at that precise time. The MonAMI default value is 25 minutes. This can be changed by setting the latest_retention attribute to the required duration, in minutes. If the data is not marked (by the type attribute) for latest queries then this has no effect.
The history retention period is the period of time after data is added that it is retained for history queries. R-GMA will guarantee to store for that period, but may retain it for longer. The MonAMI default value is 50 minutes, but this value can be changed by setting the history_retention attribute to the required duration, in minutes. If the data is not marked for history queries then this has no effect.
Security
The R-GMA service can accept commands through either an insecure
(HTTP) or secure (HTTPS) connection. With the insecure
connection, no authentication happens: anyone can insert data.
Adding data insecurely is the more simply and robust, but as
anyone can send fake data it is not recommended.
With Public Key Infrastructure (PKI), a host proves its identity with credentials that are split into two separate parts: one part is kept secret and the other is made public. The public part is the X509 certificate, which describes who the server claims to be and is signed by a trusted organisation. The secret part is the host's private key. This file must be kept securely and is needed when establishing a secure connection to verify that the server really is as claimed in the certificate.
When attempting to send data via a secure connection, the R-GMA server will only accepted connections established with a valid X509 certificate, one that the server can verify the complete trust-chain. A valid X509 host certificate has a common name (CN) that is identical to the host's fully qualified domain name (FQDN). To be useful, the certificate must have been issued by a certificate authority (CA) that the R-GMA server trusts. Trust, here, is simply that the CA's own certificate appears within the R-GMA server's CA directory (as specified within the R-GMA server's configuration).
The private key is precious: all security gained from using PKI
depends on the private key being kept secret. It is common
practice to allow only the root user (and processes running
with root privileges) access to the private key file.
However, many programs need to prove they are running on a
particular machine without running “as root”,
so cannot access the private key directly. To allow this,
short-lived (typically 1 hour) certificates, called
proxy certificates, are generated that are
signed by the host certificate. The signing process (and so,
generating proxy certificates) requires access to the host's
private key. However, once generated, these short-lived
certificates can have more liberal access policies because, if
stolen, they are only valid for a short period.
Unless the host's private key is directly readable (which is
not recommended), MonAMI needs to have access
to a supply of valid proxy certificates so it can upload data to
an R-GMA server securely. To achieve this, an external script is
run periodically (once an hour, by default) to generate a
short-lived proxy host certificate. Some MonAMI installations
will have no X509-PKI files and no need to upload data to R-GMA.
Because of this, the script
rgma-proxy-renewal.sh (in the directory
/usr/libexec/monami) is
designed to fail quietly if there is no host key and no
certificate installed in their default locations
(/etc/grid-security/hostkey.pem and
/etc/grid-security/hostcert.pem,
respectively).
To generate a proxy certificate, the script will search for one of
the proxy generating commands
(voms-proxy-init,
lcg-proxy-init, ...) in standard locations.
It will work “out of the box” if it can find a
suitable command. If it fails, or its behaviour needs to be
adjusted, the file /etc/sysconfig/monami
should be edited to altered how the script behaves.
All the following options start RGMA_. To save
space, the RGMA_ prefix is not included in the list
below; for example, the option listed as HOST_CERT is
actually RGMA_HOST_CERT.
HOST_CERTThe location of the host certificate, in PEM format. The default value is
/etc/grid-security/hostcert.pemHOST_KEYThe location of the host private key, in PEM format. The default value is
/etc/grid-security/hostkey.pemHOST_PROXY_DIRThe absolute path to the directory in which the proxy will be stored. Any old proxy certificates within this directory will be deleted. The default value is
/var/lib/monami/rgmaHOST_PROXY_BASENAMEThe constant part of a proxy certificate filename. Proxy certificate filenames are generated by appending a number to this basename. The default value is
hostproxyand an example proxy certificate ishostproxy.849PROXY_RENEW_CMDThe absolute path to an
globus-proxy-init-like command. By default, the script will look for one of several commands within several standard locations. Unless the proxy generating command is located in a non-standard location or is called something unusual, it is not necessary to specify this option.MONAMI_USERThe user account MonAMI runs as. By default this is
monami.PERIODHow often the script is run (in hours). By default, this is 1 (i.e., one hour). This variable controls only for how long a freshly made proxy certificate is valid; to change the rate at which proxy certificates are made, the cron entry (the file
/etc/cron.d/monami-rgma) must be altered to a corresponding value.
Dealing with failures
It is possible that, for whatever reason, an R-GMA server may not be able to receive data for a period of time; for example, this might happen if the R-GMA server is down (e.g., for software upgrade) or from network failures. If a rgma target is unable to send the data, it will store the data in memory and attempt transmission later. Transmission of unsent data is attempted before sending new data and also automatically every 30 seconds.
Storing unsent data uses memory, which is a finite resource on any computer. The default behaviour on some computers is to kill programs that have excessive memory usage; those computers that do not kill such programs outright will often “swap” memory to disk, resulting much poorer performance of the computer overall.
To prevent an unavailable R-GMA server from adversely affecting MonAMI, a safety limit is placed on how much unsent data is stored. If the length of the unsent data queue exceeds this limit then the oldest data is thrown away to make space for the new data.
The default behaviour is to limit the backlog queue to 100 datatrees. How quickly this limit is reached will depend on how fast data is sent to an rgma plugin. The backlog queue limit can be altered through the backlog attribute, although a minimum backlog value of 10 is enforced.
Example usage
The following example configuration monitors the
“myservice” processes every minute and records the
number that are in running (or runable), sleep and zombie states.
The data is stored in the (fictitious) R-GMA table myServiceProcessUsage. The table has
three fields: running,
sleeping and zombie. The data delivered from the
process target (srv_procs) is uploaded to
the rgma target (srv_rgma) and matches each
of the three column names.
[process] name = srv_procs count = procs_running : myservice [state=R] count = procs_sleeping : myservice [state=S] count = procs_zombie : myservice [state=Z] [sample] interval = 1m read = srv_procs write = srv_rgma [rgma] name = srv_rgma table = myServiceProcessUsage column = running : srv_procs.count.procs_running column = sleeping : srv_procs.count.procs_sleeping column = zombie : srv_procs.count.procs_zombie
Attributes
- table string, required
the table name MonAMI will append data to.
- column string, required
the mapping between a MonAMI metric name and the corresponding R-GMA column name. In general, there should be a column attribute for each column in the corresponding R-GMA table.
The column attribute takes values like:
rgma column:metric name[options]where
metric nameoptions- rgma_home string, optional
If the usual environment variables are not specified or do not point to a valid
rgma.conffile and rgma_home has been specified, MonAMI will attempt to parse the file rgma_home/etc/rgma/rgma.conffor details on how to contact the R-GMA server.- host string, optional
the host to which MonAMI should connect for submitting data. Default value is
localhost. It is recommended that this value is only used if you do not have anrgma.conffile.- port integer, optional
the
TCPport to which MonAMI should connect when submitting data. Default value is8080when connecting insecurely and8443when connecting securely.- access string, optional
this attribute will determine whether to use
SSL/TLS-based security when connection to the R-GMA server. A value of secure will result in attemptingSSL/TLS-based mutual authentication; a value ofinsecurewill use an insecureHTTPtransport. By default, secure access will be used.- type string, optional
a comma-separated list of R-GMA queries for which the data should be a candidate. Added data will always show up during continous queries. Specifying
historywill mark the data so it is also a candidate for history queries. Similarly, specifyinglatestmarks data so it is also a candidate for latest queries.- storage string, optional
the type of storage to request. This can be either
memoryordatabase. The default value ismemory.- latest_retention integer, optional
when inserting data that is marked for “latest” queries, this is the period of time after data is added that it is guaranteed to be present. The value is in minutes, the default value is 25 minutes.
- history_retention integer, optional
when inserting data that is marked for “history” queries, this is the period of time after data is added that it is guaranteed to be present. The value is in minutes, the default being 50 minutes.
- backlog integer, optional
The maximum length of the unsent data queue whilst waiting for an R-GMA server. If the backlog of datatrees to send to an R-GMA server exceeds this value, then the oldest datatree is thrown away. The default value is 100 with a minimum value of 10 being enforced.